|
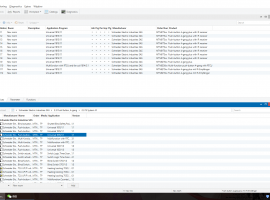
对于解析来说,常用的解析方法其实无非那么几种,正则、XPath、CSS Selector,另外对于某些接口,常见的可能就是 JSON、XML 类型,使用对应的库进行处理即可,这些规则和解析方法其实写起来是很繁琐的,如果我们要爬上万个网站,如果每个网站都去写对应的规则,那么不就太累了吗?所以智能解析便是一个需求。 什么是爬虫的智能化解析呢?顾名思义就是自动解析页面,不在慢慢一个网站一个网站的写解析规则,我们可以利用一些算法来计算出来页面上的特定元素的位置和样式。但是智能化解析是非常难的一项任务,比如你给别人看一个网页的一篇文章,人可以迅速获取到这篇文章的标题是什么,发布时间是什么,正文是哪一块,或者哪一块是广告位,哪一块是导航栏等内容。可是把把文章拿给机器来识别呢?,它面临仅仅是一系列的 HTML 代码而已。那么机器是是融合了那些方面的信息来做到智能化提取的呢?这些信息包括标题、正文、 时间、广告等。
- 标题、一般它的字号是比较大的,而且长度不长,位置一般都在页面上方,而且大部分情况下它应该和 title 标签里的内容是一致的。
- 正文、它的内容一般是最多的,而且会包含多个段落 或者图片标签,另外它的宽度一般可能会占用到页面的三分之二区域,并且密度会比较大。
- 时间、不同语言的页面可能不同,但时间的格式是有限的,如 2019-02-20 或者 2019/02/20 等等,也有的可能是美式的记法,顺序不同,这些也有特定的模式可以识别。
- 广告、它的标签一般可能会带有 ads 这样的字样,另外大多数可能会处于文章底部、页面侧栏,并可能包含一些特定的外链内容。
另外还有一些特点就不再一一赘述了,这其中包含了区块位置、区块大小、区块标签、区块内容、区块疏密度等等多种特征,另外很多情况下还需要借助于视觉的特征,所以说这里面其实结合了算法计算、视觉处理、自然语言处理等各个方面的内容。如果能把这些特征综合运用起来,再经过大量的数据训练,是可以得到一个非常不错的效果的。 例如下图,这是 Safari 中自带的阅读模式自动解析的结果 对于智能解析,下面分为四个方法进行了划分:
- readability 算法,这个算法定义了不同区块的不同标注集合,通过权重计算来得到最可能的区块位置。
- 疏密度判断,计算单位个数区块内的平均文本内容长度,根据疏密程度来大致区分。
- Scrapyly 自学习,是 Scrapy 开发的组件,指定⻚页⾯面和提取结果样例例,其可⾃自学习提取规则,提取其他同类⻚页⾯面。
- 深度学习,使⽤用深度学习来对解析位置进⾏行行有监督学习,需要⼤大量量标注数据。
如果能够容忍一定的错误率,可以使用智能解析来大大节省时间。 本文介绍的内容比较粗略,一般来说解析模型只能针对特定的网络训练解析模型,比如新闻,电商产品页。所以不同类型的网页,所需要的特征变量有较大差别。针对不同特点类型数据,需要大家自己花时间去探索和实践。 随着数据时代和智能化时代到来,爬虫作为重要的数据来源,自身需要一些技术提升来适应时代的要求,这也就对爬虫工程师提出更高的要求。成文粗陋,权且当做抛砖引玉,欢迎大家留言讨论。
| 














 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡