来源:EET电子工程专辑
概要:Google深入剖析其TPU和测试基准显示比目前的商用芯片更快至少15倍的速度,并提供更高30倍的效能功耗比(P/W)。
网络巨擘谷歌(Google)日前指出,该公司的Tensor处理器(TPU)在机器学习的测试中,以数量级的效能优势超越英特尔(Intel)的Xeon处理器和Nvidia的绘图处理器(GPU)。在一份长达17页的报告中,Google深入剖析其TPU和测试基准显示比目前的商用芯片更快至少15倍的速度,并提供更高30倍的效能功耗比(P/W)。
去年五月,Google宣布其ASIC设计是为了加快各种应用在其数据中心服务器的推论作业。现在,该公司将在今年6月的一场计算机架构大会中,透过一篇论文首度公开对于此芯片及其效能的深入研究。
这份报告提供了有关加速器与Google多元神经网络工作负载的深度观察,并建议工程师在此快速成长的领域中投注更多的学习。
曾带领超过70位工程师团队设计TPU 的知名硬件工程师Norman P. Jouppi说:“我们希望聘请一些优秀的工程师,并让他们了解我们正在进行高质量的工作,同时也让云端客户知道我们的实力。”
该计划的其中一位负责人员是美国加州伯克利大学(U.C. Berkeley)退休教授David Patterson,他同时也是一位资深的处理器架构师,在日前一场硅谷的工程师聚会中介绍了这份报告。Google还在部落格中发布Jouppi所撰写关于此芯片的文章。
如今Google的数据中心仍采用此芯片。不过,关于该芯片使用的范围与未来计划加强的部份,Jouppi并不愿透露任何细节。
这款40W功率的TPU是一款采用28纳米工艺、70MHz频率运算的芯片,专为加速Google TensoRFlow 算法而设计。其主要的逻辑单元包含65,536个8位的乘积累加运算单元和24MB高速缓存,并提供每秒92兆次指令周期。
在2015年采用Google机器学习芯片而进行的测试中,相较于英特尔(Intel)的Haswell服务器处理器(CPU)和Nvidia的K80绘图处理器(GPU),采用TPU时的运作速度提高了15到30倍,效能提高了30到80倍。该报告中指出:“TPU的相对增量效能功耗比为41到83——这就是我们为什么客制化ASIC的原因,它让TPU比GPU高出25到29倍的的效能功耗比。”
2015年的测试使用了英特尔 22纳米工艺的18核心Haswell E5-2699 v3 CPU,其频率频率(速度)为2.3GHz,热设计功耗(TDP)为145W。Nvidia K80 GPU功耗为150W,频率频率最高到875MHz。

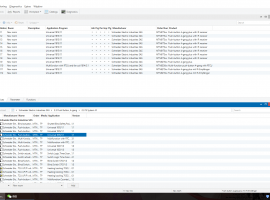
图1:TPU(星形)在神经网络推论作业的效能超越英特尔Haswell处理器(圆形),以及Nvidia K80(三角形)
TPU内部揭密
在该报告中提到,TPU所达到的数量级效能优势,很少有别的厂商能做到,也可能让TPU成为特定领域架构的原型。预计接下来将会有许多追随者,而使得标准更为提高。
事实上,TPU的目标不在于提高数据处理量,而是专注于达到7毫秒(ms)的延迟,使专用加速器发挥功效,因此,它舍弃了高吞吐量的多任务通用处理器所需的许多组件,而用于执行其他许多任务。
但此ASIC芯片在能耗比的表现上不及英特尔和Nvidia的芯片。在10%的负载状况下,TPU的最大功率消耗为88%。相形之下,K80在10%负载下消耗66%的功率,而英特尔Haswell的最大功耗为56%。
Google解释,这是由于仅15个月的设计时程相对较短,使得TPU无法加入许多节能方面的功能。
数据缓冲区约占TPU的37%,媒体访问控制(MAC)组合占30%。虽然TPU比起Nvidia GPU的尺寸更小、功耗更低,但其上的MAC数量却是K80的25倍,芯片上内存容量则为其3.5倍。
TPU搭载PCIe Gen3 x16总线,并提供256位的内部数据路径。主机CPU将加速器视为浮点运算处理器,透过PCIe总线传达指令。

图2:大部份的TPU主要用于处理MAC数组,以及24MB高速缓存
TPU使用与GPU加速器相同的Tensorflow软件,开发人员可维持核心驱动器的稳定,必要时调整使用者空间的驱动程序,以因应不断改变的应用。
Google发现,持续增加的内存带宽对于效能表现的影响最大。平均来说,加速频率速度的效益不大,而当MAC扩增到512x512矩阵时,加快频率速度的效能还将微幅下降。
该报告中指出,从2015年的测试以来,英特尔已经推出14纳米CPU,Nvidia也推出16纳米GPU了。然而,TPU也可能将其外部DDR3内存升级到像K80所使用的GDDR5内存。
报告中指出:“未来的CPU与GPU在执行推论时将会更快速。采用2015版GPU内存而重新设计的TPU将会提高两倍到三倍的速度,而且比K80高出70倍、比Haswell更高200倍的效能功耗比。”
Google宣称在英特尔CPU上执行8位运算相当辛苦。报告中提到:“我们原本只有一款CPU执行8位运算的结果,因为有效地使用其AVX2整数运算指令,效果提升了3.5倍。”
由于其采用数据处理量为导向的架构,即使是改良过的GPU要达到Google的 7nm延迟目标,仍然充满挑战。同时,“这款TPU仍有很大的改进空间,所以这不是一个容易达成的目标。”

图3:ASIC芯片支持PCIe Gen 3 x16总线,并搭载DDR3内存
开发人员掌握多元化信息
该报告中提到,研究人员受到热门的ImageNet比赛吸引,已经变得过于投入卷积神经网络(CNN)。现实世界的应用采用更广泛的神经网络类型,报告并强调,多层感知(MLP)占Google AI开发工作的61%。“虽然大部份的架构师一直在加速CNN设计,但这部份只占5%的工作负载。”
“虽然CNN可能很常见于边缘设备,但卷积模型的数量还赶不上数据中心的多层感知(MLP)和长短期内存(LSTM)。我们希望架构师尽可能地加速MLP和LSTM设计,这种情况类似于当许多架构师专注于浮点运算效能时,大部份的主流工作负载仍由整数运算主导。”
Jouppi说:“我们已经开始与一些大学合作,扩大提供免费模式。”但他并未透露内容细节。
这篇报告回顾了二十多年来神经网络的相关数据,包括其竞争对手——微软(Microsoft)基于FPGA的Catapult计划,加速了网络作业。最初的25W Catapult在200MHz频率上运作3,926个18位MAC,并且以200MHz 频率速度执行5MB内存。Google表示,以Verilog语言设计的固件比起使用TensorFlow软件来说效率更低。

图4:TPU卡可插入服务器的SATA插槽上
TPU计划于2013年开始,当时并以FPGA进行了试验。该报告中提到:“我们舍弃FPGA,因为我们当时发现它和GPU相比,在效能上不具竞争力,而TPU比起GPU在相同速度或甚至更快的速度下,可以达到更低的功耗。”
尽管二十多年来,神经网络终于在最近从商用市场起飞了。
Jouppi说:“我们所有人都被这蓬勃发展的景象吓到了,当初并未预期到会有如此大的影响力。一直到五、六年以前,我都还一直抱持怀疑态度…而今订单开始逐月增加中。”
相较于传统途径,深度神经网络(DNN)已经让语音识别的错误率降低了30%,这是二十年来最大的进步。这让ImageNet影像辨识竞赛中的错误率从2011年的26%降至3.5%。
该报告结论还提到,“神经网络加速器存在的理由在于效能,而在其演进过程中,如何达到良好的直觉判断,目前还为时过早。”
编译:EE Times
来源:今日头条
2017未来科技论坛暨”未来科技资助计划”发布
人工智能学家/未来科技学院与中科创星,中国科学院虚拟经济与数据科学研究中心,金融发展局等机构联合举办未来科技论坛和发起“未来科技资助计划”,联合科技企业家、风险投资家,讲解当前人工智能,互联网,脑科学,机器人最新进展,对科学家的前沿科学研究和科技创业进行支持。为诞生中国的重大原始科学创新和科技独角兽提供燃料和催化剂。
主办单位:中国科学院虚拟经济与数据科学研究中心
承办单位:人工智能学家/未来科技学院
支持单位:中科创星,泰智会,常州经开区金融发展局
会议时间:2017年4月26日
会议地点:北京市海淀区中关村丹棱街1号互联网金融中心1楼泰智会大厅
参会嘉宾:青年科学家代表,科技企业家代表,投资界代表、政府代表
未来科技论坛议题:
1.邀请人工智能,互联网,脑科学,机器人等方面的著名科学家进行最新科技前沿进展的报告
2.邀请著名投资人,科学家,科技企业家从不同角度阐述如何支持科学家的前沿科学研究和科技创业。
3.人工智能学家/未来科技学院发布科学资助平台“Funding Future”,并与合作伙伴联合启动“未来科技资助计划”
报名参加论坛请点击“阅读原文” | 














 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡