|
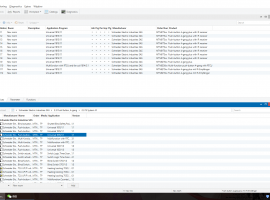
分析大量数据只是使大数据与以前的数据分析不同的部分原因之一。让我们来从下面三个方面看看。 我们每天都在吃饭,睡觉,工作,玩耍,与此同时产生大量的数据。根据IBM调研的说法,人类每天生成2.5亿(250亿)字节的数据。 这相当于一堆DVD数据从地球到月球的距离,涵盖我们发送的文本、上传的照片、各类传感器数据、设备与设备之间的通信的所有信息等。 这也就是为什么“大数据”成为如此常见的流行词的一个重要原因。简单地说,当人们谈论大数据时,他们指的是获取大量数据的能力,分析它,并将其转化为有用的东西。 1.确切的说,什么是大数据? 当然,大数据还远远不止这些? · 通常从多个来源获取大量数据 · 不仅仅是大量的数据,而且是不同类型的数据,同时也有多种数据,以及随时间变化的数据,这些数据不需要转换成特定的格式或一致性。 · 以一种方式分析数据,允许对相同的数据池进行分析,从而实现不同的目的 · 尽快实现所有这一切 在早些时候,这个行业提出了一个缩略词来描述这四个方面中的三个:VVV,体积(数量巨大),多样性(不同类型的数据和数据随时间变化的事实)和周转率(速度)。 2. 大数据与数据仓库: VVV的缩写词所忽略的是数据不需要永久更改(转换)的关键概念——进行分析。这种非破坏性分析意味着,组织可以分析相同的数据连接池以不同的目的,并可以收集到不同目的的来源分析数据。 (备注:数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。) 相比之下,数据仓库是专门为特定目的分析特定数据,数据结构化并转换为特定格式,原始数据在该过程中基本上被销毁,用于特定目的,而不是其他被称为提取,转换和加载(ETL)。 数据仓库的ETL方法有限分析具体数据进行具体分析。 当您的所有数据都存在于您的交易系统中时,这是非常好的,但在当今互联网连接的世界中,数据来自无处不在。 信息是现代企业的重要资源,是企业运用科学管理、决策分析的基础。目前,大多数企业花费大量的资金和时间来构建联机事务处理OLTP的业务系统和办公自动化系统,用来记录事务处理的各种相关数据。据统计,数据量每2~3年时间就会成倍增长,这些数据蕴含着巨大的商业价值,而企业所关注的通常只占在总数据量的2%~4%左右。 因此,企业仍然没有最大化地利用已存在的数据资源,以至于浪费了更多的时间和资金,也失去制定关键商业决策的最佳契机。于是,企业如何通过各种技术手段,并把数据转换为信息、知识,已经成了提高其核心竞争力的主要瓶颈。 数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。数据仓库是决策支持系统(dss)和联机分析应用数据源的结构化数据环境。数据仓库研究和解决从数据库中获取信息的问题。数据仓库的特征在于面向主题、集成性、稳定性和时变性。 但是,不要认为大数据会使数据仓库过时。大数据系统可以让您在很大程度上处理非结构化数据,但是所得到的查询结果与数据仓库的复杂程度是不一样的。毕竟,数据仓库是为了深入数据而设计的,它之所以能够做到这一点,是因为它已经将所有数据转换成一种一致的格式,让您可以像构建立方体一样进行深入查询。 多年来,数据仓库供应商一直在优化他们的查询引擎,以回答典型的业务环境问题。大数据可以让你从更多的数据源中获取更多的数据,但分辨率要低一些。因此,在未来一段时间内,我们将与传统的数据仓库一起并存。 3.技术突破大数据背后 为了完成大数据量,品种,非破坏性使用和速度的四个方面,包括分布式文件系统(hadoop)的开发,一种意识到不同数据的方法(Google的Map、Reduce以及最近的Apache Spark),以及云/互联网基础设施,用于根据需要访问和移动数据。 直到大约十几年前,在任何一个时间都不可能操纵比较少的数据。(嗯,我们都认为数据仓库当时是巨大的,随着互联网的产生和连接的数据到处都是这样的背景)。对数据存储的数量和位置的限制、计算能力以及处理来自多个数据源的不同数据格式的能力使得这项任务几乎不可能完成。 然后,在2003年左右的时间里,Google的研究人员开发了Map、Reduce。 这种编程技术通过首先将数据映射到一系列键/值对来简化处理大数据集,然后对类似的键执行计算以将它们减少到单个值,以数百或数千个低位并行处理每个数据块 成型机。 这种巨大的并行性允许Google从越来越大量的数据中产生更快的搜索结果。 在2003年,Google创造了两个突破,使得大数据成为可能:一个是Hadoop,它由两个关键服务组成: · 使用Hadoop分布式文件系统(HDFS)可靠的数据存储 · 使用称为Map、Reduce的技术进行高性能并行数据处理。 Hadoop运行在商品,无共享服务器的集合上。您可以随意添加或删除Hadoop集群中的服务器; 系统检测并补偿任何服务器上的硬件或系统问题。 换句话说,Hadoop是自我修复的。 尽管发生系统更改或故障,它可以提供数据并运行大规模,高性能的处理作业。 使用Hadoop,仍然需要一种存储和访问数据的方法。 这通常通过诸如MongoDB之类的NoSQL数据库(如CouchDB或Cassandra)完成,该数据库专门处理分布在多台计算机上的非结构化或半结构化数据。与在数据仓库中不同的是,大量数据和类型的数据融合成统一格式并存储在单个数据存储中,这些工具不会改变数据的底层性质或位置 – 电子邮件仍然是电子邮件,传感器数据仍然是 传感器数据 – 可以几乎存储在任何地方。 尽管如此,在使用多台机器的数据库中存储大量的数据并不是很好,直到你做了一些事情。 这就是大数据分析的原理。像Tableau,Splunk和Jasper BI这样的工具可以让您解析这些数据,以识别模式,提取意义并揭示新的见解。 你所做的事情会因你的需要而有所不同。
| 
















 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡