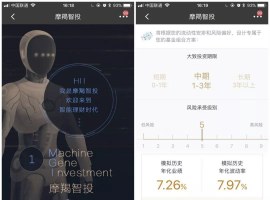
未来索引
-
资料下载
-
方案下载
-
KNX World
-
素材下载
-
智育未来
-
影音资源
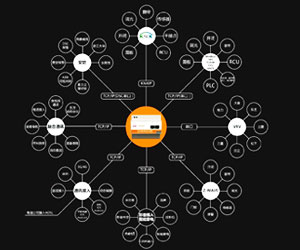



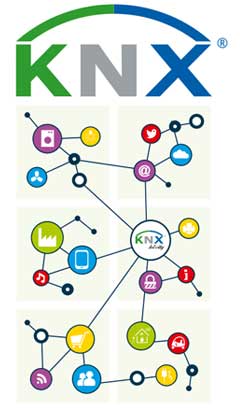











 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡