|
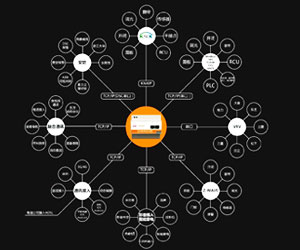
进入21世纪,面对网络时代信息的爆炸式增长,中文信息处理作为一项基础性、普适特性的信息技术,面临着挑战和再次发展的机遇,在互联网时代则显示出其优势。它的开发利用关系到我国今后信息产业乃至社会经济的发展和安全,具有巨大的经济价值和社会价值。 中文信息处理是中文(包括汉语和少数民族语言)语言学和信息技术的融合,它是一门用计算机对汉语(包括口语和书面语)进行转换、传输、存贮、分析等加工的科学。中文信息处理与语言学、计算机科学、心理学、数学、控制论、信息论、声学、自动化技术等多种学科相联系,是自然语言信息处理的一个分支,需要以大量的语言知识、背景知识为依据,对中文信息的人脑处理过程进行模拟。其中,“中文”是指中国通用的所有语言种类,包括汉语及其他少数民族的语言:但一般都是指汉语。“信息”是指能通过视觉、听觉、嗅觉、味觉、触觉等器官或仪器获取,并有一定交际功能的东西,“信息”是不确定性的减少,是负熵。所谓“处理”,是指用计算机对信息进行各种加工,主要的是图像信息和语言信息的识别、模拟、分析、转换和传输。 中文信息处理技术自动化水平的提高,将大大促进我国科技、国民经济和社会发展,同时使中华民族的文化在信息时代得到新的发展。未来无疑应当加强中文信息处理技术的研发投入与政策倾斜。我国的中文信息处理技术还有自身一系列急需解决的基础研究和应用技术问题。这些问题如果从现在起还得不到切实的加强,我们在中文信息处理事业中仅有的一些优势,就要迅速失去,那将给我国造成极大的损失。 中文信息处理应用研究的问题,比如信息输入中的键盘输入和汉字识别发展已经成熟,但语音识别却很实现,困难是要适应不同人之间的语音变化以及外界的噪音干扰;中文信息处理研究分散而且存在着低层次重复、缺乏统一规范和标准的问题;现代汉语研究领域和计算机领域的隔绝状态没有出现根本性改变;汉语文和少数民族语言文字的信息处理技术与国际水平相比,还有相当大的差距。特别是自主知识产权的成果还不多;语言资源和成果的共享还有很大局限,网络上对公众开放的中国语言文字资源还很少,远不能满足我国国民经济发展和信息化事业对中文信息处理技术的要求等等。 北京理工大学大数据搜索与挖掘实验室张华平主任研发的NLPIR大数据语义智能分析技术是满足大数据挖掘对语法、词法和语义的综合应用。NLPIR大数据语义智能分析平台是根据中文数据挖掘的综合需求,融合了网络精准采集、自然语言理解、文本挖掘和语义搜索的研究成果,并针对互联网内容处理的全技术链条的共享开发平台。 NLPIR大数据语义智能分析平台主要有精准采集、文档转化、新词发现、批量分词、语言统计、文本聚类、文本分类、摘要实体、智能过滤、情感分析、文档去重、全文检索、编码转换等十余项功能模块,平台提供了客户端工具,云服务与二次开发接口等多种产品使用形式。各个中间件API可以无缝地融合到客户的各类复杂应用系统之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD等不同操作系统平台,可以供Java,Python,C,C#等各类开发语言使用。 随着信息技术在我国社会生活各个领域应用的深入,中文信息处理正在成为人们工作和生活中不可或缺的手段,中文信息处理将具有更加广阔的市场。这将促使中文信息处理方面的高效中文搜索引擎、实时机器翻译、大规模中文文本处理、跨平台中西文自动识别转换、泛中文语义理解、中文电子商务等技术实现重大突破。中文信息处理已成为我国信息技术研究、发展、应用和产业的基础,在互联网日益成长的今天,中文信息处理技术将会更加成熟并创新。
| 













 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡